
 Nov 18, 2025
Nov 18, 2025 

Cet article est le premier d’une série dédiée à la qualité chez Powens. Dans celui-ci, nous explorons notre cadre de priorisation des anomalies.
Il était une fois les bugs
La plupart des ingénieurs s’accorderont à dire qu’aucune machine n’est parfaite — surtout dans le logiciel. Les bugs font partie de l’équation et existeront toujours. Les logiciels sont des systèmes complexes, et l’expérience confirme systématiquement le théorème de Derrick : plus un système est complexe, plus la probabilité qu’il échoue est élevée.
Vous pouvez opter pour une politique de “zéro bug”. Cela signifie essentiellement ne pas livrer de nouveau code tant que tous les bugs connus, même mineurs, ne sont pas corrigés. Cette approche peut fonctionner si votre logiciel est peu complexe et n’a que très peu de dépendances externes (par exemple, si les bugs sont majoritairement endogènes et non dus à des tiers).
Mais d’un point de vue business, cela peut s’avérer une erreur stratégique. Comme d’autres industries nécessitant beaucoup d’investissements avant de viser la profitabilité, le logiciel est soumis à des dynamiques de monopole — surtout lorsqu’il bénéficie d’effets de réseau. Aujourd’hui, une poignée de géants de la tech représente 30 % de la valeur du S&P. Mais contrairement à des secteurs traditionnels comme le pétrole ou la pharma, les barrières à l’entrée sont plus faibles dans le logiciel, et le rythme d’innovation y est fulgurant. En clair, quelques développeurs talentueux peuvent rapidement devenir des concurrents sérieux — en particulier si votre produit est peu différencié. Pour garder votre avance, vous devez donc investir en continu dans de nouvelles fonctionnalités et de nouveaux produits.
L’Open Banking, justement, coche plusieurs de ces cases. Il repose sur de nombreuses dépendances externes (connecteurs vers des APIs et des sites bancaires), est ultra-concurrentiel et assez banalisé — les produits concurrents se ressemblent beaucoup. Les effets de réseau sont cruciaux, car les clients choisissent souvent le fournisseur qui couvre le plus grand nombre de banques. Et pour ne rien arranger, les APIs bancaires et les sites auxquels nous nous connectons sont loin d’être des modèles de stabilité.
En théorie, cela devrait conduire à un taux d’anomalies supérieur à celui d’autres produits logiciels. Et pourtant, ce n’est pas vraiment le cas. Voici pourquoi.
Ce que cela signifie pour Powens
Avant d’entrer dans le détail, un mot sur le vocabulaire : chez Powens, on évite de parler de “bugs”, car la majorité de nos anomalies sont importées — elles ne sont pas dues à un défaut dans notre code, mais à un événement extérieur que nous ne contrôlons pas.
Maintenant que les termes sont posés, passons aux chiffres. Powens maintient aujourd’hui 5 millions de connexions bancaires actives en Europe et en Amérique latine, et en ajoute chaque mois entre 50 000 et 100 000. En un mois, notre système de monitoring remonte en moyenne 30 000 anomalies sur différents types de connexions (ex. : un seul compte non rafraîchi ou une banque entière indisponible pour certains utilisateurs). Cela représente un taux d’erreur de 0,6 %, soit 99,4 % de succès — une très bonne performance pour un produit connecté à plus de 1 800 sources de données externes.
Si l’on regroupe ces anomalies par causes racines uniques, cela donne environ 500 problèmes uniques par mois, soit 1,2 défaut par KLOC (1 000 lignes de code) — une norme équivalente à celle des meilleurs systèmes d’entreprise. En termes absolus, notre niveau de qualité est donc élevé, voire exceptionnel si l’on considère que la majorité de nos anomalies provient de l’extérieur. Mais nos clients, à juste titre, ne jugent pas en absolu.
En relatif, la situation est différente : notre équipe peut corriger environ 100 anomalies par mois, laissant 400 anomalies non résolues — soit un taux de correction d’environ 20 %.
Que faire dans ce cas ?
- Première option : augmenter le nombre de développeurs dédiés à la maintenance des connecteurs — au détriment des autres chantiers d’amélioration continue (infra, sécurité, modèles API…).
- Deuxième option : réduire le nombre de connecteurs proposés. Moins de connecteurs, c’est moins d’anomalies. Mais c’est aussi moins d’usage, donc moins de MRR.
- Troisième option : prioriser les anomalies à fort impact (volume d’utilisateurs affectés ou impact sur l’expérience), même si cela signifie faire des choix différents de ceux attendus par certains clients.
Alors, laquelle choisiriez-vous ?
Système de hiérarchisation des anomalies de Powens
Spoiler : nous les avons toutes choisies. L’an dernier, nous avons mis en place un cadre unifié qui combine ces trois approches dans un système cohérent de résolution des anomalies, articulé autour de trois principes : (i) alignement des attentes sur la réalité ; (ii) focalisation sur l’impact ; et (iii) gestion du chaos.
Aligner les attentes sur la réalité
Aligner les attentes sur la réalité, c’est avant tout faire preuve de clarté : sur ce que nous pouvons faire, sur ce que nous ne pouvons pas faire — et partager cette réalité avec nos clients. Ils doivent comprendre les choix que nous faisons — surtout les plus difficiles — ainsi que les raisons qui les motivent.
Nous avons donc commencé par réévaluer l’ensemble de nos connecteurs. Et le constat est simple : certains connecteurs sont plus importants que d’autres. Les grandes banques, par exemple, génèrent davantage d’usage. D’autres établissements, plus “exotiques” (petites banques mutualistes, nouvelles plateformes d’investissement…), ont une portée plus limitée.
Certains connecteurs sont également plus instables ou plus coûteux à maintenir, quel que soit leur volume d’usage : le site de la banque change souvent, l’API est peu fiable, ou bien il existe des enjeux stratégiques — par exemple, un connecteur essentiel au lancement d’un nouveau marché ou clé pour un segment client spécifique.
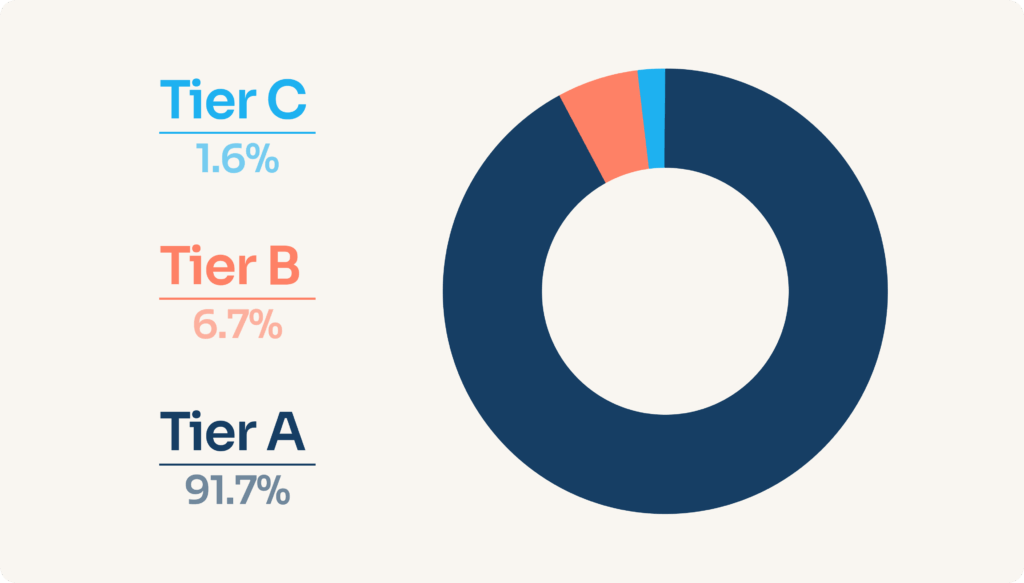
Part des connexions bancaires actives par connecteur niveau
Pour prendre en compte cette diversité, nous avons mis en place un système de hiérarchisation des connecteurs :
- Tier A : connecteurs très importants
- Tier B : connecteurs importants
- Tier C : connecteurs moins importants
Le niveau (“Tier”) de chaque connecteur est défini comme le produit de trois facteurs : usage × charge de maintenance × importance stratégique
Une fois cette hiérarchisation posée, nous avons défini des objectifs de qualité réalistes par niveau, basés sur notre KPI principal : le taux de succès de connexion d’un nouveau compte.
Nous avons pris un engagement chiffré pour les connecteurs A et B uniquement. Pour les connecteurs C, nous restons en mode “best effort” – en d’autres termes, nous intervenons lorsque les problèmes de Tier A et de Tier B sont maîtrisés. Bien sûr, cela peut être difficile à entendre pour les clients concernés. Mais dans les faits, c’est déjà ce qui se passe — autant donc l’assumer de manière transparente. Et il est important de noter que plus de 90 % de l’usage global passe par des connecteurs de Tier A.
C’est pourquoi nous communiquons à nos clients les Tiers et les objectifs des connecteurs, afin qu’ils sachent à quel niveau de qualité s’attendre. Il ne s’agit pas d’une liste définitive. Chaque trimestre, nous examinons les retours de nos clients, analysons les données historiques et réévaluons la liste actuelle des connecteurs. Certains sont promus à un niveau supérieur, d’autres rétrogradés, et certains même supprimés.
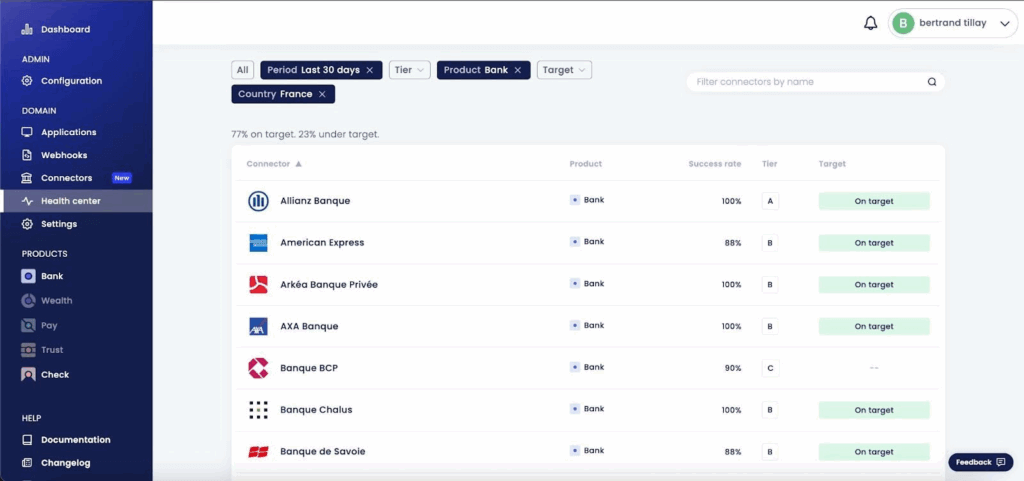
Les niveaux de connectivité, les objectifs et les taux de réussite actuels sont disponibles sur notre tableau de bord de santé
Encore une fois, tout cela implique d’accepter qu’il n’est pas physiquement possible de corriger tout ce que l’on aimerait corriger. Il faut faire des choix — et ces choix doivent être assumés publiquement. Ainsi, non seulement nous alignons nos attentes sur la réalité, mais nous visons également à aligner celles de nos clients sur cette même réalité.
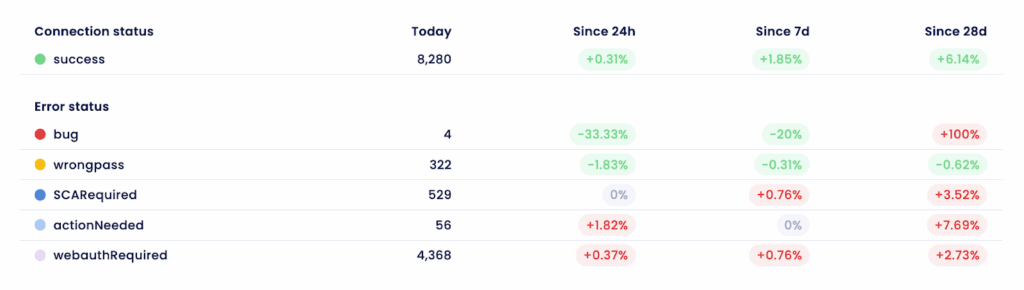
Pour chaque connecteur, nous fournissons des statistiques détaillées sur le taux de réussite et les catégories d’anomalies
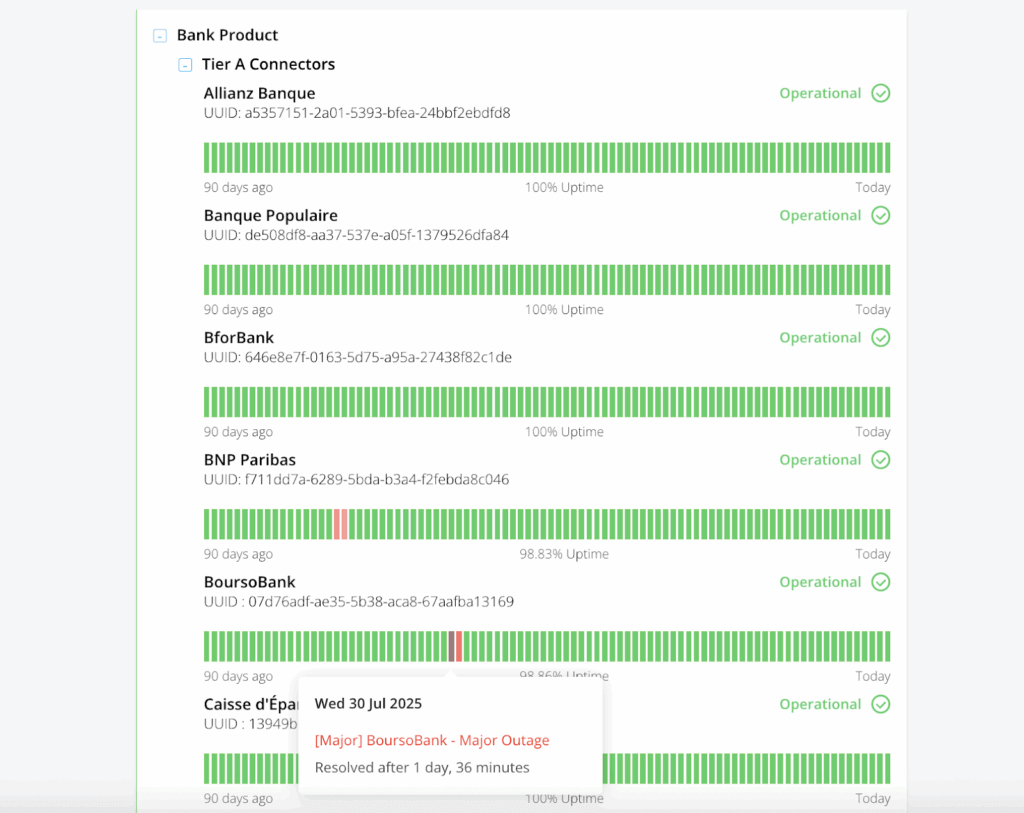
Notre page d’état publique fournit un historique de la disponibilité des connecteurs
Se concentrer sur l’impact
La hiérarchisation des connecteurs n’est qu’une dimension. L’autre, c’est la nature même de l’anomalie (qualitative) et son nombre d’occurrences (quantitatif).
D’un point de vue du volume, c’est simple : plus une anomalie se produit souvent, plus elle est prioritaire. Une erreur qui empêche 100 000 utilisateurs de rafraîchir leurs données est évidemment plus critique qu’un bug touchant 1 000 utilisateurs.
Mais du point de vue qualitatif, tout dépend du contexte métier et de l’usage des données. De manière générale, nous avons établi trois grandes catégories d’anomalies :
- Un “échec de création de nouveau compte” (l’impossibilité pour un utilisateur d’ajouter un compte pour la première fois)
- Un “échec d’actualisation de compte” (impossibilité d’actualiser les données d’un compte déjà connecté) et
- Un “problème de qualité des données” (certaines des données récupérées sont incorrectes).
Et nous avons défini un ordre de criticité : nouveau compte > rafraîchissement > qualité des données
Combinons maintenant tout ça. Un exemple simple : un connecteur de Tier A empêche tous les utilisateurs d’ajouter un nouveau compte. Ce connecteur représente 15 % du trafic total. La priorité est évidemment maximale.
Mais comparez maintenant deux cas :
- Une panne à 100 % sur un connecteur de Tier B, représentant 2 % du trafic
- Une défaillance partielle : 30 % des utilisateurs d’un connecteur de Tier A ne peuvent plus rafraîchir leurs données, soit 4 % du trafic total
Le choix devient plus complexe.
C’est pourquoi nous avons élaboré une matrice décisionnelle qui attribue des numéros de priorité allant de P0 (le plus important) à P25 (le moins important) pour tous les types de problèmes possibles. La série de numéros est séquentielle : il n’est pas possible d’avoir deux types d’anomalies ayant tous deux la priorité P5.
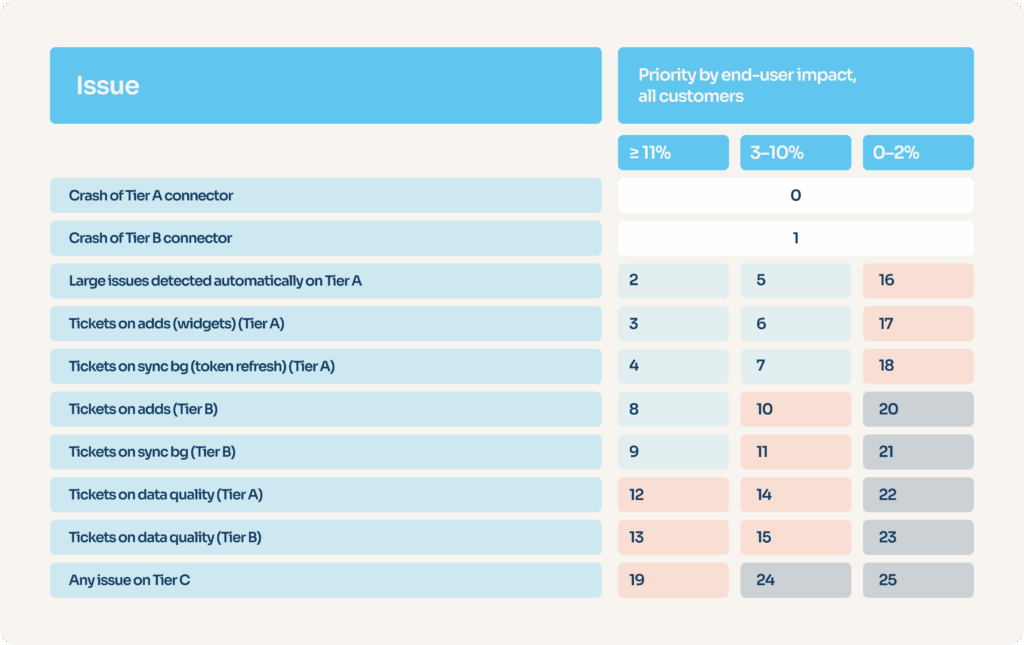
Notre outil de surveillance peut calculer automatiquement l’impact sur l’utilisateur final et déterminer la nature de l’anomalie concernée en analysant les “logs” (journaux d’erreurs). Une priorité brute est alors définie automatiquement, pouvant ensuite être ajustée manuellement par l’équipe de maintenance du connecteur.
Gérer le chaos
Tout cela est très bien, mais comment pouvons-nous nous adapter aux problèmes qui surviennent de manière imprévisible ? Et quand peut-on décider de ne pas corriger une anomalie, plutôt que de la conserver pour plus tard ?
Certains mois, nous avons plusieurs “P0” en même temps (crashs importants de connecteurs). D’autres mois, nous avons à peine un “P2”. Et comment trouver l’équilibre entre la correction des bugs des connecteurs et les tâches à plus long terme, comme l’amélioration du système de surveillance, par exemple ? Des travaux de développement interrompus de manière aléatoire ne mèneront à rien, et vous risquez de sous-investir dans votre plateforme — ce qui finira par générer davantage d’instabilité.
Vous avez besoin, là encore, d’un système suffisamment flexible pour augmenter les ressources de manière tactique (le nombre de développeurs disponibles pour corriger les bugs des connecteurs), mais suffisamment rigide pour éviter d’interrompre le travail d’amélioration de la qualité à long terme — qui, sinon, serait stoppé dès que les choses commenceraient à s’accélérer.
À cette fin, nous avons décidé de classer tous les numéros de priorité en quatre catégories : “critique”, “élevé”, “moyen” et “faible”. En fonction de la catégorie de priorité, le chef de produit de l’équipe de maintenance des connecteurs dispose d’une marge de manœuvre plus ou moins importante.
Parmi les pouvoirs dont il peut faire usage, on peut citer : le refus d’une tâche (choisir de ne jamais la corriger), l’interruption de tout autre type de tâche de développement — y compris à long terme — ou même, dans les cas les plus critiques, la demande d’assistance de tout développeur de l’entreprise, quelle que soit son équipe, jusqu’à ce que le problème soit résolu.
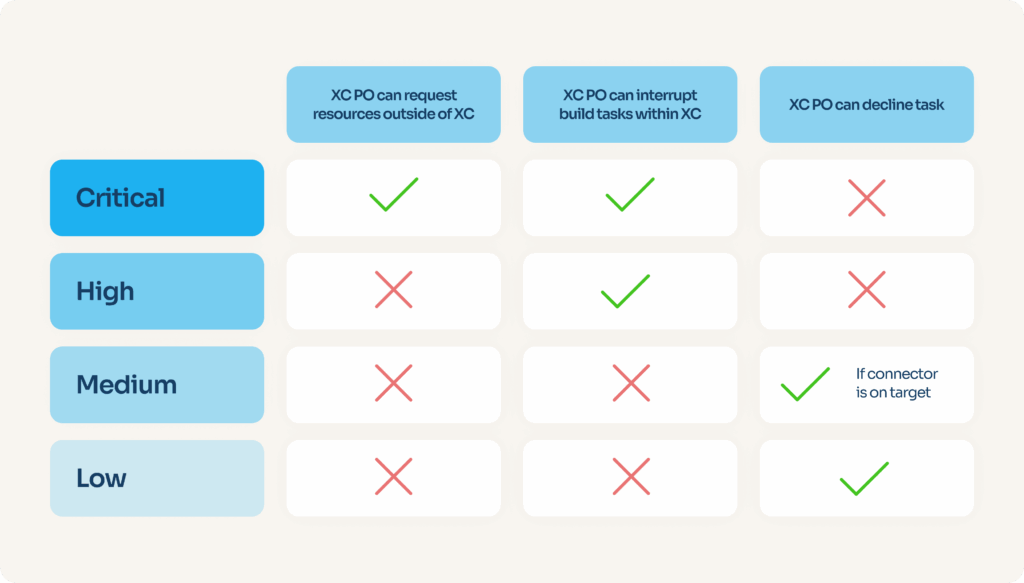
“XC” désigne “X-Connectors”, l’équipe chargée de la connectivité. “PO” désigne “Product Owner”, le rôle responsable des décisions relatives aux produits au sein de l’équipe.
Conclusion
La concurrence est forte dans le domaine de l’Open Banking, et Powens occupe une position de leader depuis un certain temps déjà. L’une des raisons de ce succès est notre engagement en faveur de la qualité et du service client. Pour bon nombre de nos clients, les services que nous fournissons sont essentiels à leur activité. Leur tolérance aux anomalies est faible — et à juste titre. Il est de notre devoir d’être transparents et de faire tout notre possible pour répondre à leurs attentes.
Notre système de hiérarchisation et de priorisation n’est qu’une des nombreuses initiatives allant dans ce sens. Nous sommes impatients de vous faire découvrir les autres — alors restez à l’écoute.












